带软阈值函数的两层卷积神经网络凸对偶理论分析(中文,English)
熊春燕1, 张超星2,卢梦丽2,于小烔2,曹健2, 陈忠2,郭迪3,屈小波2,*
1 厦门大学,电磁声学研究院,福建省等离子体与磁共振重点实验室,中国,厦门.
2 厦门大学,电子科学系,福建省等离子体与磁共振重点实验室,生物医学智能云研发中心,中国,厦门.
3 厦门理工学院,计算机与信息工程学院,中国,厦门.
* Email: quxiaobo <at> xmu.edu.cn
引用
Chunyan Xiong, Chaoxing Zhang, Mengli Lu, Xiaotong Yu, Jian Cao, Zhong Chen, Di Guo, and Xiaobo Qu, Convex Dual Theory Analysis of Two-Layer Convolutional Neural Networks with Soft-Thresholding, IEEE Transactions on Neural Networks and Learning Systems, DOI: 10.1109/TNNLS.2024.3353795
概要
软阈值函数已被广泛应用于神经网络。它的基本网络结构是带软阈值函数的两层卷积神经网络。由于网络的非线性和非凸性,训练过程严重依赖于对网络参数的合适初始化,导致难以获得全局最优解,这给医学图像等对像素敏感领域带来了挑战。
为了解决这个问题,我们设计了一个凸对偶网络。从理论上分析了网络的凸性,证明强对偶成立,并在仿真数据及实测数据上验证强对偶成立,对偶网络不依赖于初始化方式和优化器的选取,并且比现存两层网络更快收敛。这个工作提供了一个新的方式凸化软阈值网络。进一步,我们还推导了带并行结构的深层软阈值网络的对偶模型。
主要内容
针对原始软阈值网络模型非凸,最优解的获得依赖于初始化方式以及优化器选取的问题,本文设计了凸对偶网络模型(图1)。首先,利用拉格朗日对偶理论推导出其弱对偶模型,然后,为了给网络训练过程提供更准确的表示,本文基于软阈值函数特性,在不改变非线性变换后目标值的情况下,构造对角矩阵,将非线性运算转化为线性运算(图2),划分超平面。接着,结合凸优化理论证明强对偶成立。实测数据的实验结果表明,强对偶成立 (图3),对偶网络不依赖于初始化方式 (图4) 及优化器 (图5) 的选取。
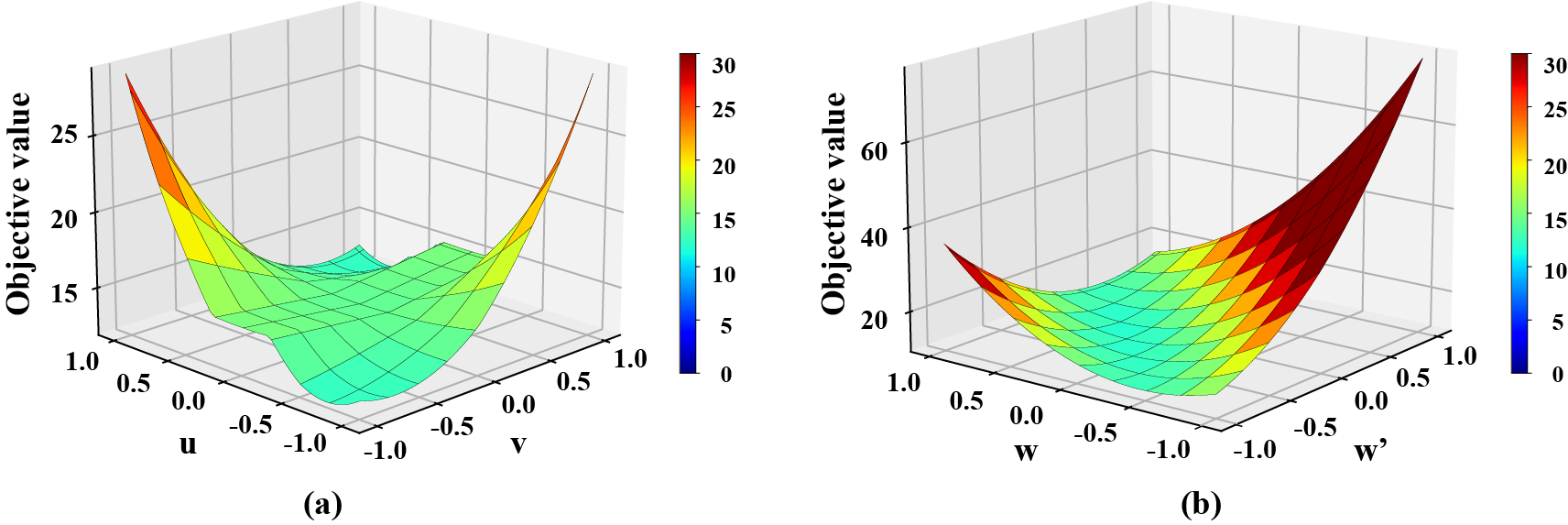
图1. 在一维数据集上,用ADAM训练的两层原始软阈值网络和对偶软阈值网络目标值。假设 $x =[−1,2,0,1,2]^{T}, y =[2, 1, 2, 1, 2]^{T}$,分别是输入和输出。(a)非凸原始软阈值网络, (b)凸对偶软阈值网络。
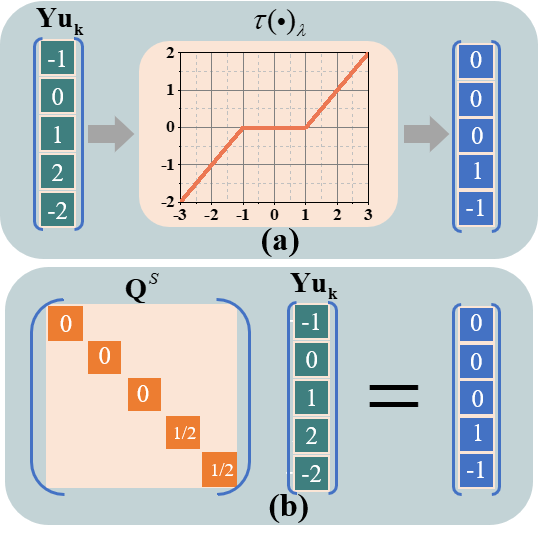
图2. 示例: 将非线性运算转换为线性运算。 (a)原始软阈值网络中的软阈值函数,(b)对偶软阈值网络中的对角矩阵。
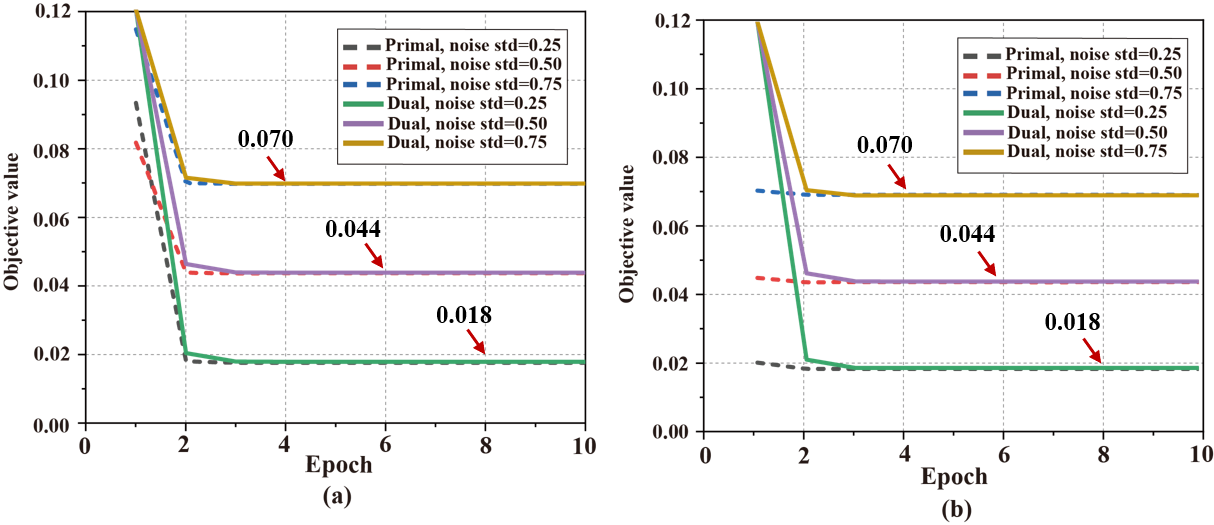
图3. 验证零对偶间隙(强对偶)成立,即当原始软阈值网络与对偶网络模型目标值都达到全局最优时,二者目标值非常接近。(a)和(b)分别为训练阶段和测试阶段(网络被训练后)的目标值。
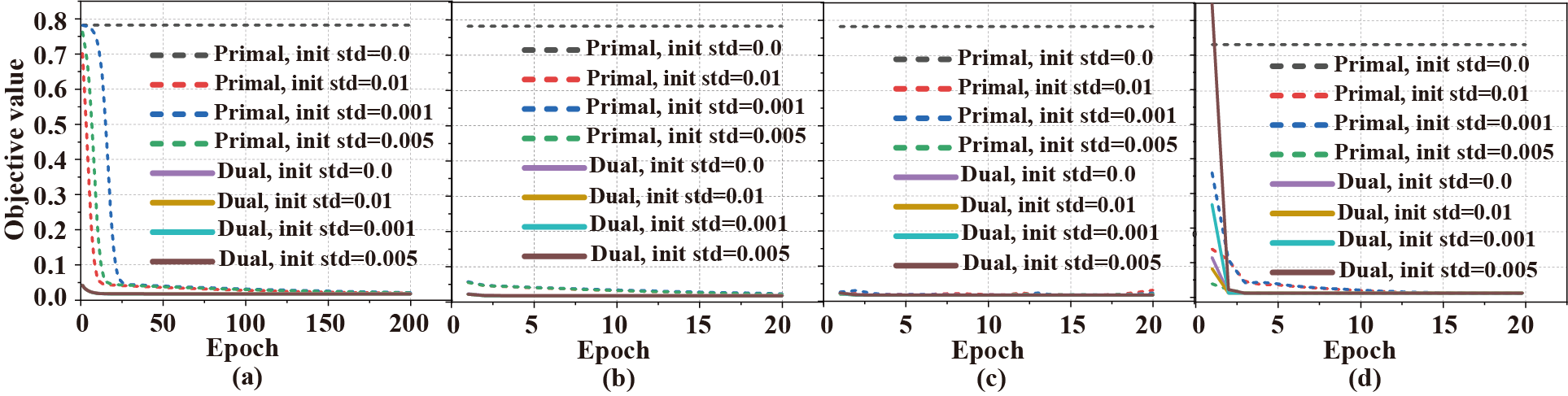
图4. 不同优化器和不同初始化方式下的原始网络和对偶网络的目标值。(a)-(d)分别是在优化器为SGDM,AdaGrad, RMSProp 和 Adam下的结果。
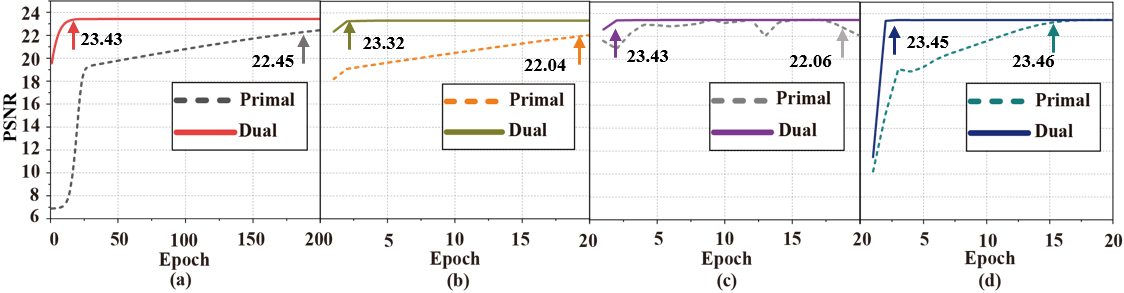
图5. 不同优化器下原始网络和对偶网络的PSNR性能。(a)-(d)为不同优化器下的结果,优化器分别使用SGDM、AdaGrad、RMSProp和Adam。注: PSNR是网络训练后400张图像上的平均。所有网络参数初始化服从正态分布 $N(0, 0.001^{2})$。
代码下载
所提方法的python代码可以从这里下载。
致谢
这项工作得到了,国家自然科学基金(61971361, 62122064, 62331021 和 62371410),福建省自然科学基金(2023J02005和2021J011184),厦门大学校长基金(20720220063), 厦门大学南强拔尖人才计划的资助。
参考文献
[1] Z. Wang, D. Guo, Z. Tu, Y. Huang, Y. Zhou, J. Wang, L. Feng, D. Lin, Y. You, T. Agback, V. Orekhov, and X. Qu, “A sparse model-inspired deep thresholding network for exponential signal reconstruction–application in fast biological spectroscopy,” IEEE Trans. Neural Netw.
Learn. Syst., vol. 34, no. 10, pp. 7578–7592, 2023.
[2] M. Pilanci and T. Ergen, “Neural networks are convex regularizers: Exact polynomial-time convex optimization formulations for two-layer networks,”in Proc. Int. Conf. Mach. Learn. (ICML), 2020, pp. 7695–7705
[3] A. Sahiner, M. Mardani, B. Ozturkler, M. Pilanci, and J. Pauly, “Convex
regularization behind neural reconstruction,” arXiv:2012.05169, 2020.
[4] E. J. Candes and T. Tao, “Decoding by linear programming,” IEEE Trans. Inf. Theory, vol. 51, no. 12, pp. 4203–4215, 2005
[5] M. Pilanci and T. Ergen, “Neural networks are convex regularizers: Exact polynomial-time convex optimization formulations for two-layer networks,” in Proc. Int. Conf. Mach. Learn. (ICML), 2020, pp. 7695–
7705..